A GPU NVIDIA H200 Tensor Core pode ser descrita como a versão mais ambiciosa da arquitetura Hopper, a mesma usada na GPU H100, criada para cargas intensas de inteligência artificial e computação científica. O que a H200 fez foi manter esse esqueleto e resolver o ponto mais crítico: a memória.
Ela é a primeira GPU do mundo com HBM3e, uma tecnologia em que os chips de memória são empilhados próximos ao processador, permitindo tráfego de dados muito mais rápido e estável que as memórias tradicionais. Neste caso, estamos falando de 141 GB de VRAM e 4,8 TB/s de largura de banda.
A NVIDIA H200 melhora o que a H100 já fazia bem. Ela atende LLMs gigantes, simulações científicas complexas e contextos de texto extensos, mas permite que tarefas que antes exigiam várias GPUs rodem agora em uma única placa.
Entenda onde a H200 se diferencia da H100, quais recursos impactam de verdade, como ela entrega nos benchmarks e em quais cenários faz sentido investir nela.
NVIDIA H200 vs H100: o que mudou?
A comparação entre a H200 e a H100 mostra bem a lógica da NVIDIA: não foi preciso mudar a arquitetura para entregar ganhos reais, mas sim resolver o maior gargalo.
A diferença mais evidente está na memória. A H100 oferecia 80 GB de VRAM, enquanto a H200 mais que dobra esse número para 141 GB, agora em HBM3e. Isso significa mais espaço para armazenar modelos inteiros sem precisar dividi-los entre várias placas.
Outro salto está na largura de banda, 43% maior que o H100. Esse incremento evita que o processador fique ocioso esperando dados, acelerando o treinamento de LLMs e o processamento em cargas de HPC.
Apesar desse crescimento, o consumo energético permanece na faixa de ~700W, igual ao da H100. Na prática, você tem mais desempenho por watt e um menor custo total de propriedade (TCO), já que é possível atender a mesma carga de trabalho com menos GPUs.
Por fim, a compatibilidade é total: a H200 funciona no mesmo ecossistema de hardware e software da H100. Data centers que já operam com Hopper conseguem migrar sem refazer infraestrutura ou reescrever código.
| Característica | NVIDIA H100 | NVIDIA H200 | O que muda na prática |
|---|---|---|---|
| Memória (VRAM) | 80 GB HBM3 | 141 GB HBM3e | Modelos maiores cabem em menos GPUs |
| Largura de banda | 3,35 TB/s | 4,8 TB/s | Menos gargalos, processamento mais rápido |
| Eficiência energética | ~700W TDP | ~700W TDP | Mais desempenho sem aumentar consumo |
| Arquitetura | Hopper (GH100) | Hopper (GH100) | Mesmo núcleo, mas com memória otimizada |
| Compatibilidade | HGX H100, software CUDA | HGX H200, software CUDA | Upgrade fácil, sem refazer infraestrutura |
Características da NVIDIA H200
As especificações da NVIDIA H200 explicam por que ela se tornou referência para LLMs em grande escala e HPC avançado. Além do salto de memória, ela traz recursos que aumentam velocidade, eficiência e flexibilidade no uso real.
| Especificação | H200 | O que significa na prática |
|---|---|---|
| Memória | 141 GB HBM3e | Modelos enormes podem rodar em uma única GPU, sem precisar fragmentar em várias placas. |
| Largura de banda da memória | 4,8 TB/s | Dados circulam mais rápido, acelerando treino e inferência em IA generativa. |
| Tensor Cores (4ª geração) | 528 | Núcleos dedicados para IA, otimizados para redes neurais e modelos de linguagem. |
| CUDA Cores | 14.592 | Núcleos de propósito geral para cálculos massivos em paralelo. |
| TFLOPS FP64 | 34 | Desempenho em cálculos científicos de alta precisão. |
| TFLOPS FP32 | 67 | Performance em cálculos comuns de IA e gráficos. |
| TFLOPS Tensor (FP16) | 1.979 | Potência para treinar IA em precisão reduzida, acelerando tempo de treino. |
| TFLOPS Tensor (FP8) | 3.958 | Performance máxima em IA generativa e LLMs, com suporte ao Transformer Engine. |
| TDP (Potência Máxima) | Até 700W | Mesmo consumo da H100, mas com muito mais desempenho por watt. |
| Interconexão | NVLink / NVSwitch | Comunicação ultrarrápida (até 900 GB/s) entre múltiplas GPUs em clusters. |
| Formatos | SXM e PCIe | Flexibilidade para implantação em diferentes tipos de servidores. |
Os Tensor Cores, junto com o Transformer Engine, foram ajustados para lidar melhor com modelos de linguagem. Eles processam matrizes de forma mais eficiente, acelerando treino e inferência sem aumentar o consumo.
A segunda geração do MIG (Multi-Instance GPU) permite “fatiar” a placa em até sete partes independentes. Na prática, é como ter várias GPUs menores dentro de uma só, cada uma com memória dedicada.
A H200 também traz as DPX Instructions, um conjunto de instruções específicas no chip. Elas funcionam como “atalhos” para cálculos recorrentes em IA e em simulações científicas.
E, para quem precisa escalar clusters, o NVLink + NVSwitch garante a conexão entre várias GPUs, permitindo troca de dados a até 900 GB/s. Essa velocidade evita gargalos quando o modelo é grande demais para caber em apenas uma placa.
Benchmarks e desempenho da H200
Quando colocamos a GPU NVIDIA H200 lado a lado com a H100 e a A100, os benchmarks mostram acelerações consistentes em LLMs, inferência e workloads científicos, chegando a multiplicar resultados.
Em inferência de modelos de linguagem, como o Llama-2 70B, a H200 chega a ser quase 2× mais rápida que a H100 com lotes maiores, aproveitando sua memória superior. Em outros casos de IA generativa, comparada à A100, ela alcança ganhos expressivos, até ~18× mais desempenho dependendo da tarefa e configuração.
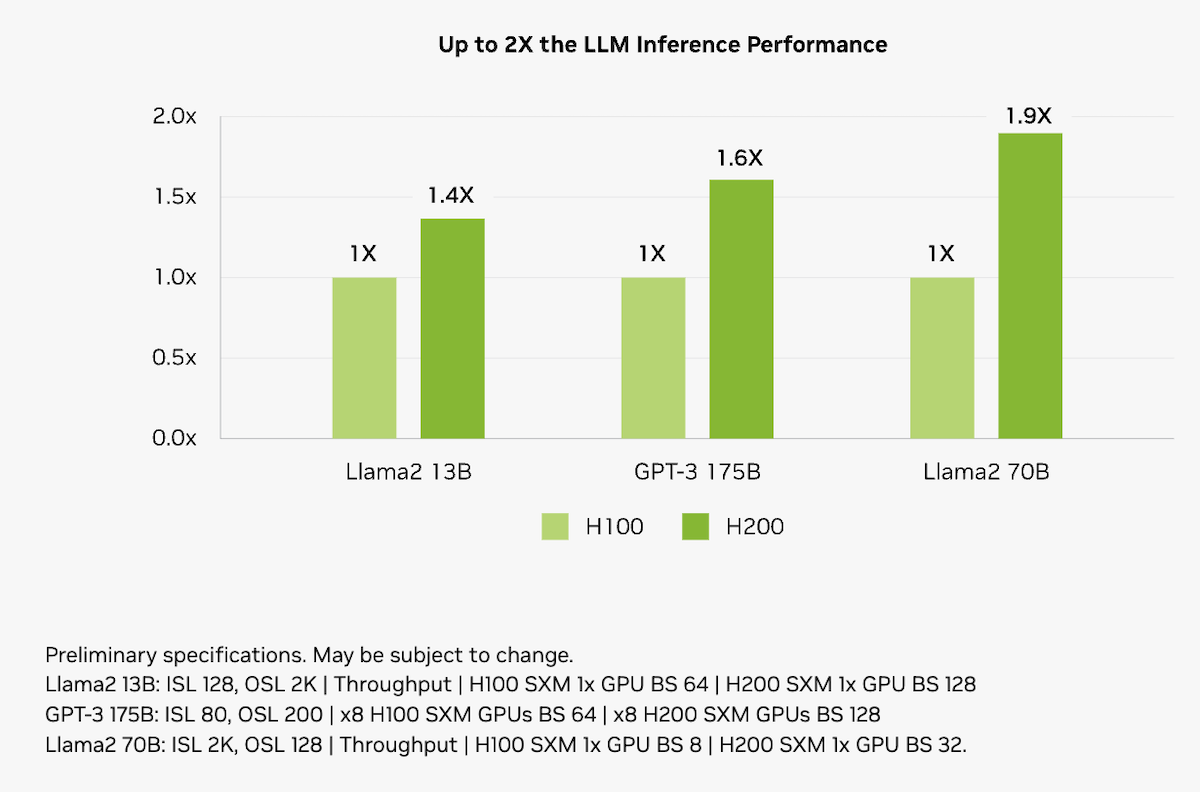
LLM Inference Performance (Llama-2 e GPT-3). Source: nvidia.com
Em cargas de HPC, a H200 mostra o quanto evoluiu: pode rodar até 110× mais rápido que CPUs em benchmarks específicos e ainda superar a H100 em até 2× de desempenho médio.

HPC Performance Comparison (A100 vs H100 vs H200). Source: nvidia.com
O impacto vai além da performance bruta. A H200 permite entregar o mesmo throughput com menos placas, reduz a latência em inferência e ainda corta custos de operação. Em cargas de LLMs, por exemplo, pode trazer economia de até 50% em energia e TCO quando comparada à H100.

HPC Performance Comparison (A100 vs H100 vs H200). Source: nvidia.com
Quando a NVIDIA H200 faz sentido?
Se a dúvida é quando dar o salto da H100 para a H200, pense nos seguintes pontos:
- Seu projeto envolve LLMs de larga escala ou contextos longos (16k–100k tokens).
- Você precisa de batch sizes maiores para acelerar treino e melhorar convergência.
- Já enfrentou gargalos de memória e paralelismo em GPUs anteriores.
- O custo por requisição de inferência está alto e precisa cair.
- Seu workload inclui HPC avançado (clima, fluidos, análises científicas).
- A infraestrutura exige escalabilidade com menor TCO, sem aumentar consumo de energia.
Se a maioria desses itens se aplica, a NVIDIA H200 é o caminho lógico. A H100 segue atendendo bem projetos menores, mas a H200 entrega a robustez necessária para missão crítica e expansão futura.
Fale com o time da EVEO e descubra como rodar IA generativa e HPC em escala com a segurança de quem já sustenta as maiores operações do país.

Perguntas frequentes sobre a NVIDIA H200
1. O que é a GPU NVIDIA H200?
A NVIDIA H200 é uma GPU de classe data center da arquitetura Hopper. O diferencial está na memória HBM3e de 141 GB, que permite rodar modelos de IA muito maiores e simulações científicas complexas em uma única placa, com mais velocidade e estabilidade.
2. Qual a diferença entre H200, H100 e A100?
A H200 se diferencia da H100 e da A100 principalmente pela memória e largura de banda. Contra a H100, oferece quase o dobro de VRAM e 40% mais velocidade. Já em relação à A100, o salto é ainda maior, com ganhos de até 18x em cenários de IA generativa. Isso significa rodar modelos e lotes maiores, com menos placas e menor custo por operação.
3. Por que a H200 é indicada para LLMs?
A H200 é indicada para LLMs porque resolve as duas maiores dores desse tipo de projeto: tamanho do modelo e throughput. Com 141 GB de VRAM, cabe até redes com centenas de bilhões de parâmetros em uma GPU. E com 4,8 TB/s de largura de banda, alimenta os núcleos sem gargalo, acelerando treino e inferência.
4. E na inferência, qual a vantagem real?
A vantagem da H200 na inferência é permitir atender mais usuários simultâneos e contextos muito mais longos. Isso reduz latência, aumenta o throughput e melhora o custo por requisição. Para aplicações de IA em tempo real, significa mais eficiência com menos GPUs.
5. Preciso comprar uma H200 para usar?
Não, não é necessário comprar uma H200. Como é um hardware de altíssimo custo e feito para escala, a melhor opção é usar via provedor. Na EVEO, você tem acesso a servidores com NVIDIA H200 sob demanda, em Data Centers Tier III e com SLA total, pagando apenas pelo que precisa.
6. Para quais cenários a H200 faz sentido?
A H200 faz sentido em projetos de IA generativa e HPC que exigem muito mais memória e throughput. Exemplos:
-
Treino e inferência de LLMs de última geração com batch sizes maiores e contextos de até 100k tokens.
-
HPC avançado em clima, fluidos, genômica e simulações científicas.
-
Empresas que precisam reduzir TCO sem aumentar consumo de energia.
-
Workloads de missão crítica que pedem continuidade operacional e escalabilidade.




Deixe um comentário